2024-02-12_Prismatic VLMs - Investigating the Design Space of Visually-Conditioned Language Models
| Karamcheti 等 - 2024 - Prismatic VLMs Investigating the Design Space of .pdf| 2024-02-12 | Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, Dorsa Sadigh | URL | arxiv
基于LLaVA系列:Visual Instruction TuningLLaVA-1.5做的Ablation!
提供了Codebase,复现LLaVA-1.5,可以使用?
1 Data
VSR consists of challenging True/False questions about individual spatial relationships in diverse scenes (e.g., “the cake is at the edge of the dining table”); this is an especially challenging task, with most existing models failing to outperform the majority class baseline (51%).
TallyQA consists of questions that assess a VLM’s ability to count objects described in language, with expressions that range in complexity. Finally, POPE consists of targeted Yes/No questions that assess a VLM’s propensity to hallucinate.
2 Ablations
2.1 Single-Stage Training
直接进入Instuction Tuning(Frozen ViT)即可!效果差不多!
- 根本不需要Caption data,也不需要第一阶段。
是不是因为Evaluation的benchmark里有一半是训练时用过的?
2.2 Full Finetune ViT?
掉点!可能数据量不够
2.3 ViT & Image Preprocessing
SigLip略强于CLIP-ViT
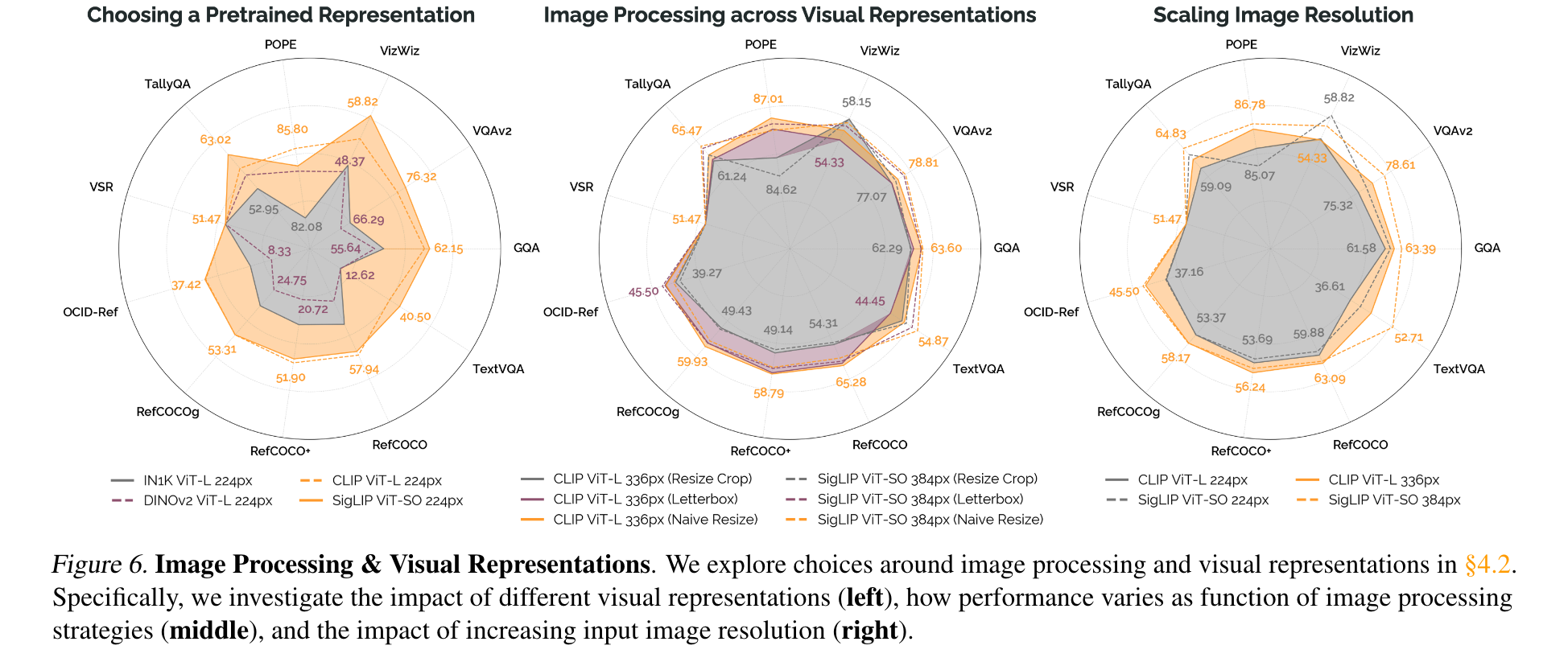
llava的pad to square,和不管长宽比的naive resize相比,差不多!
2.4 Fuse CLIP/SigLIP & DINOv2
直接channel concat,然后调整MLP,对MLP来说几乎没有参数增加。在其他benchmark上效果都好了,但是在TextVQA上大幅度掉点!为什么?
- 可能是预训练的图片域的问题!!
2.5 base or Instruction-tunedLLM?
base LLM的效果甚至更好!
3 Abstract
Visually-conditioned language models (VLMs) have seen growing adoption in applications such as visual dialogue, scene understanding, and robotic task planning; adoption that has fueled a wealth of new models such as LLaVa, InstructBLIP, and PaLI-3. Despite the volume of new releases, key design decisions around image preprocessing, architecture, and optimization are underexplored, making it challenging to understand what factors account for model performance – a challenge further complicated by the lack of objective, consistent evaluations. To address these gaps, we first compile a suite of standardized evaluations spanning visual question answering, object localization from language, and targeted challenge sets that probe properties such as hallucination; evaluations that provide calibrated, finegrained insight into a VLM’s capabilities. Second, we rigorously investigate VLMs along key design axes, including pretrained visual representations and quantifying the tradeoffs of using base vs. instruct-tuned language models, amongst others. We couple our analysis with three resource contributions: (1) a unified framework for evaluating VLMs, (2) optimized, flexible code for VLM training, and (3) checkpoints for all models, including a family of VLMs at the 7-13B scale that strictly outperform InstructBLIP and LLaVa v1.5, the state-of-the-art in open-source VLMs.